On Monday, June 10, 2024 at their annual World Wide Developer Conference (WWDC) Apple announced "Apple Intelligence", their own flavour of AI integration into their operating systems.
Emphasis should probably go into integration, as the experience that was demoed at WWDC felt like every feature we are used to on our devices was augmented in a way or another by AI. AI is also able to orchestrate those features and use multiple apps and functionalities to achieve what the user wanted.
As someone who has a love/hate relationship with Siri, this is only good news, Siri will become way more powerful and able to understand what you want to do.
This post is not going to be an overview of Apple Intelligence from the users perspective though (for which I suggest the excellent blog post from Simon Willison Thoughts on the WWDC 2024 keynote on Apple Intelligence) but will explore key concepts such as the Semantic Index, App Intents Toolbox, and foundational model adaptations utilized by Apple.
Architecture
With what was presented in the keynote, theplatform state of the union the content in introducing apple foundation models we can derive a bit of the architecture that powers Apple Intelligence.
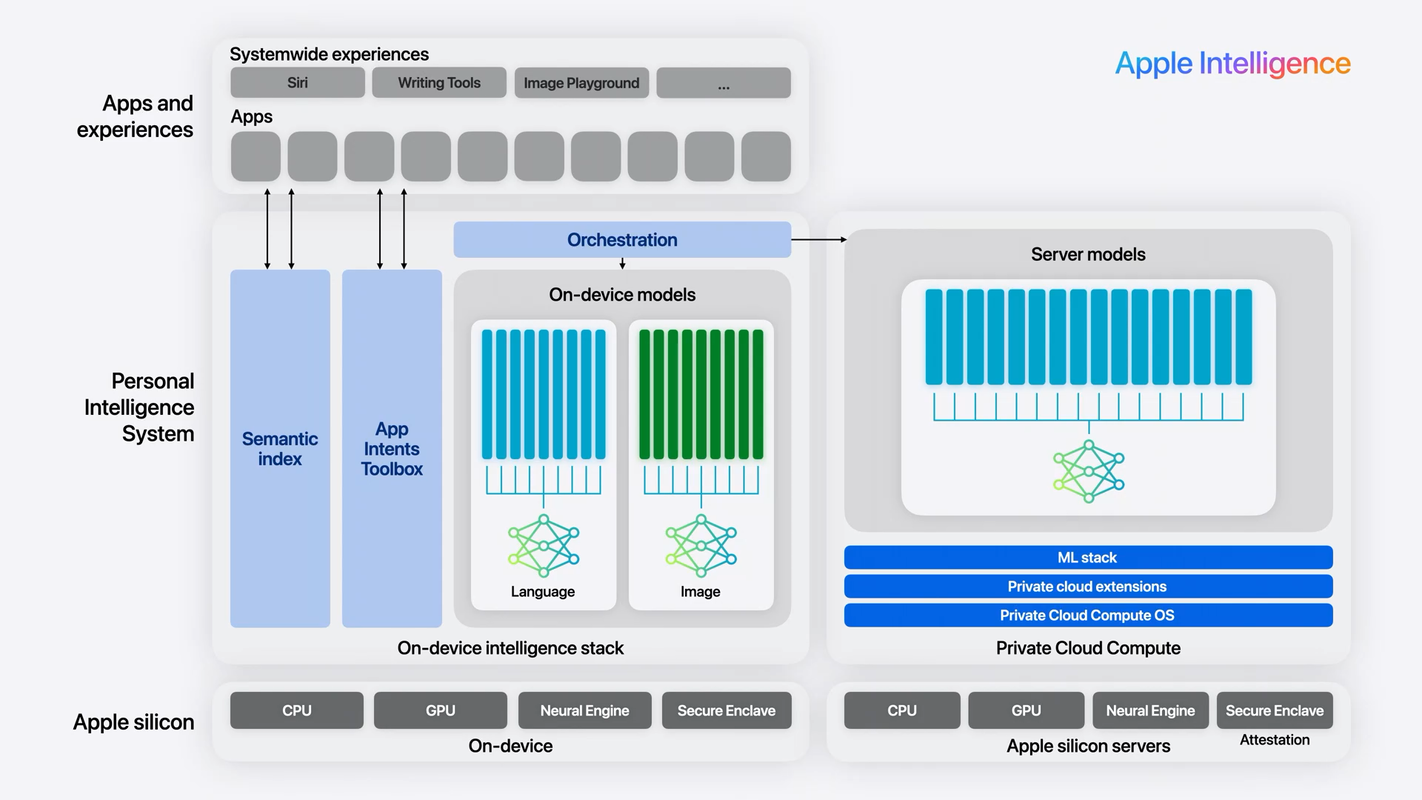
In the diagram above, we can see that the architecture has 3 layers:
- Apps and Experiences: features that the users sees and interacts with
- Personal Intelligence System: what runs on device and on Apple's servers
- Apple Silicon: the specialised Apple hardware that powers the intelligence layer and the security between on-device and cloud communication.
Apps and systemwide experiences are for example writing tools (summarization, rewriting, etc), image playground (to generate images and "genmojis") and Siri.
Personal Intelligence System
Apps and systemwide experiences interact with the Personal Intelligence System by reading from and writing to the "Semantic Index" and the "App Intents Toolbox". Then there is a orchestration layer on device that decides whether to use on-device or server models.
Let's break down these components.
Semantic Index
What Apple calls a Semantic Index is probably a vector database storing embeddings.
An "embedding" is a vector of numbers representing objects like text, images, audio and video into a multidimensional space. By computing the distance between two embeddings, you can see if two concepts are related. You can read more on embeddings in this Stackoverflow Blog Post.
Computing the distance between embeddings is usually compute intensive, especially if you are trying to surface "the closest embedding" in a collection of many of those.
To alleviate the problem, there we tend to look for the Approximate Nearest Neighbour (ANN).
Vector databases are databases specialized into storing vectors in a way that makes this search as efficient as possible.
Examples in the opensource world of these databases are Chroma and Qdrant.
App Intents Toolbox
The "App Intents Toolbox" is a way for apps to declare their capabilities so that they can be leveraged by the model. This is leveraging a technique called "tool use", which comes in two variants: single step and multi step. For single step tool use (think "write an email") it's usually referred to as "function calling", while for multi step it's commonly referred to as "agents".
With function calling, you make available to the model a list of tools that the model can "call". Based on the prompt, the model chooses whether to use a tool or not, and if it chooses to do so, it returns what tool to use and with what parameters. Based on that, the system will call the tool, get the result and return that to the user. In Apple's terms, what happens is that the user interacts with the "Personal Intelligence System" via Siri or an App, the model that apple uses within the system will check the "App Intent Toolbox" to see if there is any app or system feature that can satisfy the request, call it with the parameters exposed in the App Intents API, and surface the result to the user. For example, a query like "show me the pictures of my dog in Dublin" will interact with the Images app via the intent toolbox, filter the pictures by selecting only those tagged (by another model at a separate time) as my dog, with the geo location set to Dublin, and return the app view with those pictures displayed.
Agents capture more nuanced use cases, by taking multiple steps of "function calling" on behalf of the user, so queries like "send the pictures of my dog in Dublin to my mom via email" will first call the images app, and then the email app, and the user is presented with the email pre-populated with the pictures.
Both function calling and agents are available in the API of the most popular models (e.g. OpenAI or Google Gemini) and in the opensource world as well, with models such as Cohere's Command-R specialized in tool use, and frameworks such as Langchain that help building complex agent applications.
Orchestration
The orchestration layer is an on-device model whose only task is to decide whether to use one of the many on device or server models based on what the user or the system is trying to do. This is similar to the agents described above, but in this case the "tools" to use are other models!
Models
Individually, the on-device and server models are all multimodal models, with the key difference being the size of the model and the compute power required to run them.
Apple describes their model architecture as having foundation models + adapters.
The modeling happens in different phases:

Data collection and pre-processing
Apple collects licensed data and scraped data by their own web crawler, for which they provide an opt out by configuring the robots.txt file on the website. They do some pre-processing and feed it to the pre-training.
Pre-training
Pre-training happens using AXLearn, a framework built on top of Google's JAX and Tensorflow's XLA. This allows them to run the training on GPUs and TPUs. Apple lists a bunch of techniques that they use to achieve efficient pre-training, by splitting the work across multiple machines:
- Data Parallelism: Splitting data across multiple machines to train faster.
- Tensor Parallelism: Breaking down the model itself across multiple machines.
- Sequence Parallelism: Dividing long sequences of data to process them in parts.
- Fully Sharded Data Parallel (FSDP): Distributing both data and model pieces in a way that uses resources most efficiently.
These techniques are well explained in the HuggingFace docs, which cover Multiple GPUs and Parallelism and the Fully Sharded Data Parallel (FSDP) method.
Post-training
After pre-training, Apple refines the model with "post-training", using a mix of reinforcement learning with human feedback (RLHF) and training on synthetic data.
RLHF is a technique that became really popular with the release of ChatGPT, and consists in incorporating human feedback to align the model to human preferences. Once the model is pre-trained, humans interact with it and provide feedback on its performance, usually in terms of ranking different responses to the same prompt, or assigning a score. Based on the feedback the model receives a reward or a penalty, and these rewards or penalties are used to update the model's behaviour (this is typical of reinforcement learning, the model will try to optimize to receive as many rewards as possible over time). There are different ways to build this, there is a good overview on HuggingFace's blog.
Training on synthetic data is also a way to improve the model output, by feeding the model with data that is generated by a machine. The advantage of this is that the generated data is deterministic, and can be produced in high quantities. I suggest reading this paper from Google Deepmind to learn more about the current state of the art.
There is also the possibility of mixing the two, by using Reinforcement Learning with AI Feedback, where instead of humans we can use other AIs, specialized in ranking and scoring.
Optimization
This stage is mainly focused on speed and efficiency of the models. Especially for those running on device, we want them to be able to work very fast and not draw a lot of power to not excessively consume battery. On their models page Apple lists a few techniques with which they perform these optimizations.
Grouped Query Attention
First, they mention Grouped Query Attention (GQA). There are a few concepts to unpack to understand this technique. "Attention" is a mechanism that weighs the importance of different tokens (words, images, etc) in a sentence to predict the next token to generate, and involves three key components:
- Queries: the current token or sentence that the model is currently focusing on
- Keys: the tokens that the model can potentially focus on
- Values: the actual values (could be the same as the keys) that can be used in the output
The simplest form of attention has a single "head" (a head in this context is an independent attention mechanism), and so lets the model only focus on one set of queries, keys and values. So the output can (for example) be computed by doing the dot product queries and keys to get the attention scores.
Many large language models are based on the Transformer architecture, which commonly uses "multi-head" attention (Attention is all you need). In this case there are multiple attention "heads", each focusing and prioritizing different tokens or sequences, and contributing to the final prediction. Multi-head attention is a very powerful technique because the model can focus on multiple parts of data at the same time, leading to more nuanced outputs. The issue with "multi-head" is that it's much more expensive to compute, slowing down a lot the inference times.
To speed up the process, Shazeer from Google in 2019 published Fast Transformer Decoding: One Write-Head is All You Need, which introduces "multi-query attention", which shares keys and values across all the attention heads, only changing the "query". This leads to a much more memory efficient structure, making the inference much faster.
The issue with the "multi-query attention" technique is a degradation in quality, due to the fact that the selected keys and values are the same for all heads. Grouped Query Attention is a compromise between multi-head attention (where we have distinct keys/values for each head) and multi query attention (where we share them for all heads). The compromise is reached by creating "groups" that share the same key value pairs.
Shared embedding tables
The models leverage tables that map tokens ("vocabulary") to vectors and vice-versa. By sharing them across models this allows for lower memory usage and greater inference speeds.
Apple mentions that they use a 49K vocab for on device models, and 100K for server models (which include additional language and technical tokens). For comparison, Meta's LLama 3 model uses a vocabulary of 128K tokens.
Low-bit palletization
Palletizaiton is a quantization technique to reduce the memory usage (and as a consequence reduce power usage and improve performance) by "compressing" the weight vectors using a fixed lookup table.
For example if we had a vector of floating point weights such as [0.1, 0.1, 0.2, 0.2] and a 1 bit look up table {0.1: 0, 0.2: 1} we could compress the weights into a 1bit vector [0, 1].
In particular, Apple says that they are mixing 2-bit and 4-bit palettes to achieve an average size of 3.5 bit per weight (which is much cheaper to use than the original 16 bits the model has been trained on). This usually comes at an output quality tradeoff cost, but it seems that from Apple's own benchmarks that the results are good enough (they mention that they measure the impact of these optimization with Talaria, a custom developed tool that analyses model latency and power usage to select the best bit rate).
Activation quantization
Activations are the outputs of the neurons after applying an activation function, common activation functions are ReLU, Tanh, or Sigmoid. The goal of these activation functions is to introduce a non-linearity in the neural network and allow the model to learn more complex patterns (there is a really good video on activations in Karpathy's series NN Zero to Hero).
Quantizing the activation reduces the precision of it, again reducing the memory and compute footprint. You can see how to quantize the activation function in Lei Mao's "Quantization for Neural Network" book, in the Quantized Deep Learning Layers section.
Embedding quantization
As mentioned before, embeddings are vector representations of tokens. They can also be quantized to reduce the memory footprint and improve performance!
In particular with embeddings, there is a now popular technique called "binary quantization", which converts these embeddings from float32 values into 1 bit values, significantly reducing the embeddings size. Quantizing embeddings here literally means setting a threshold of 0, and any value below 0 gets mapped to 0, and any value above is mapped to 1. This seems like a very large loss of information, but in practice for information retrieval it yields really good results (see this paper).
Another big advantage of binary embedding quantization, is that retrieval is super fast using Hamming Distance, which only requires 2 cpu cycles to retrieve the information we need.
For more details on embedding quantization, i suggest reading this HuggingFace blog post.
Efficient key-value cache update on neural engines
Neural engines are a particular part of Apple silicon that are optimized to run computations for neural networks. Here Apple doesn't give a lot of information, but certainly having a way to quickly update the cache on a GPU-like device is something that's critical for performance.
Token speculation
Apple mentions they also employ token speculation techniques, which means that they are predicting multiple likely tokens at the same time, allowing the model to explore multiple path simultaneously. This is for example useful to provide a more "real time" experience to autocompletion, by speculating on a few paths that the user could take in composing the text.
Model adaptation
Apple created foundation models for language and image generation, these models are fine-tuned for different activities that the user might do on their device and specialize themselves just in time for the task at hand. To achieve a variety of specialization personalised for the user quickly Apple uses adapters, small neural network models that can be attached to the foundation models to make them specialized on a specific task. These adapter models can be dynamically loaded into memory, cached and swapped.
Types of adaptation
Apple mentions that they adapt the attention matrices, the attention projection matrix and the fully connected layers in the point-wise feedforward networks.
Let's break down the adapation techniques that Apple mentions.
Attention matrix adaptation
As explained above, the attention matrix is what makes the model "focus" on specific tokens or sequences to predict the next one. To adapt the attention matrix means for example updating how the attention scores are computed or modify the scaling factors, to ultimately change how attention is distributed. This can be achieved either by more training on a specific domain, or training by updating only the attention scores, or using techniques such as knowledge distillation, with a "teacher" model and a "student" model, where we aim for the student model to have a similar error between teacher and student attention matrices.
Attention projection matrices adaptation
Attention projection transforms the input sequence into matrices in usually three layers (Queries, Keys and Values), which are the main components of the attention mechanism.
By inserting an adapter at the attention projection matrices layer, we add a small neural network specialized for a task that will change the matrices that are produced, influencing the final output to be more in line with the task that we have in mind. Low-rank (LoRa) adaptation is a way of achieving that, by replacing the original matrices with smaller ones, trained on the task-specific dataset. You can read more about LoRa here.
Fully connected layers in the point-wise feedforward networks adaptation
Point-wise feed-forward networks are a component of transformer models (introduced in Attention is all you need). They consist in two fully connected layers with an activation function in the middle. They are generally used to learn more complex transformations.
Inserting an adapter here means injecting them between those layers to again make the model specialise on completing specific tasks.
Evaluation and fine-tuning improvements
Given that the focus of Apple Intelligence is to augment the user experience, the main focus of Apple's evaluation pipeline is Human Evaluation. In their foundation models document, Apple provides a useful example on how they conduct the study (the example is based on the summarization task for emails vs notifications):
- the local model summarization adapter is trained on synthetic summaries generated by the more powerful server models (this is known as knowledge distillation, also mentioned previously on the optimization section)
- to evaluate the product-specific summarization (email vs notification), they sample responses for each use case, with diverse inputs, with datasets that resemble real use cases
- they run explicit tests to reduce risks related to the task (e.g. for summarization, omitting important information), and also conduct adversarial tests to identify unknown harms
- also foundation models are tested and evaluated
I suggest looking through the Evaluation section of their doc to read more about the benchmarks they ran and how they are evaluating their model performance.
Conclusion
Apple Intelligence showcases the cutting-edge AI and ML techniques that drive the next generation of user experiences, which we can all use to improve our products. By integrating a sophisticated architecture with the Semantic Index (vector store of embeddings) and App Intents Toolbox (tools for function calling and agents), Apple has created a seamless interaction environment to augment the user capabilities while using their devices.
With their optimization techniques, including Grouped Query Attention, shared embedding tables, and various quantization methods, they enhance performance and efficiency.
Apple’s use of adapters for model specialization ensures tailored user interactions while maintaining high-speed processing and low power consumption.
Finally, their evaluation loop based on a combination of human feedback and fine-tuning, allows them to further improve the user experience, which is a key focus of Apple's differentiation.
These advancements not only enhance user experience but also pave the way for more intuitive and intelligent applications. As developers, exploring these techniques can inspire innovative solutions in our own projects. I'm excited for the way forward, and cannot wait to see the finished product that will come out with iOS 18 and the new MacOs. In the meantime, I'll try to apply some of these techniques and optimizations to my projects to understand them further.
UPDATE: Apple released more details in their Apple Intelligence Foundation Language Models paper
The images in this blog post are © 2024 Apple and are used under the doctrine of fair use for purposes of commentary.